On April 15th, CESTA hosted the Workshop on Digital Humanities to Preserve Knowledge and Cultural Heritage, bringing together scholars working with a wide range of materials and methods. The workshop was convened by the Rosetta Project (ResOurces for Endangered languages Through TranslAted texts), a collaboration between Stanford English professor and Director of American Studies Shelley Fisher Fishkin, and colleagues from the Université de Lille Ronald Jenn (Professor of Translation Studies and Digital Humanities) and Amel Fraisse (Associate Professor of Information and Computer Science, Digital Humanities and Language Processing), along with Zheng Zhang (PhD student in Natural Language Processing at Université Paris-Saclay). The project builds on the work of an earlier “Global Huck” project (which aimed to collect and examine all the translations of “Huckleberry Finn”) by using that collection as a large parallel corpus for developing NLP resources.
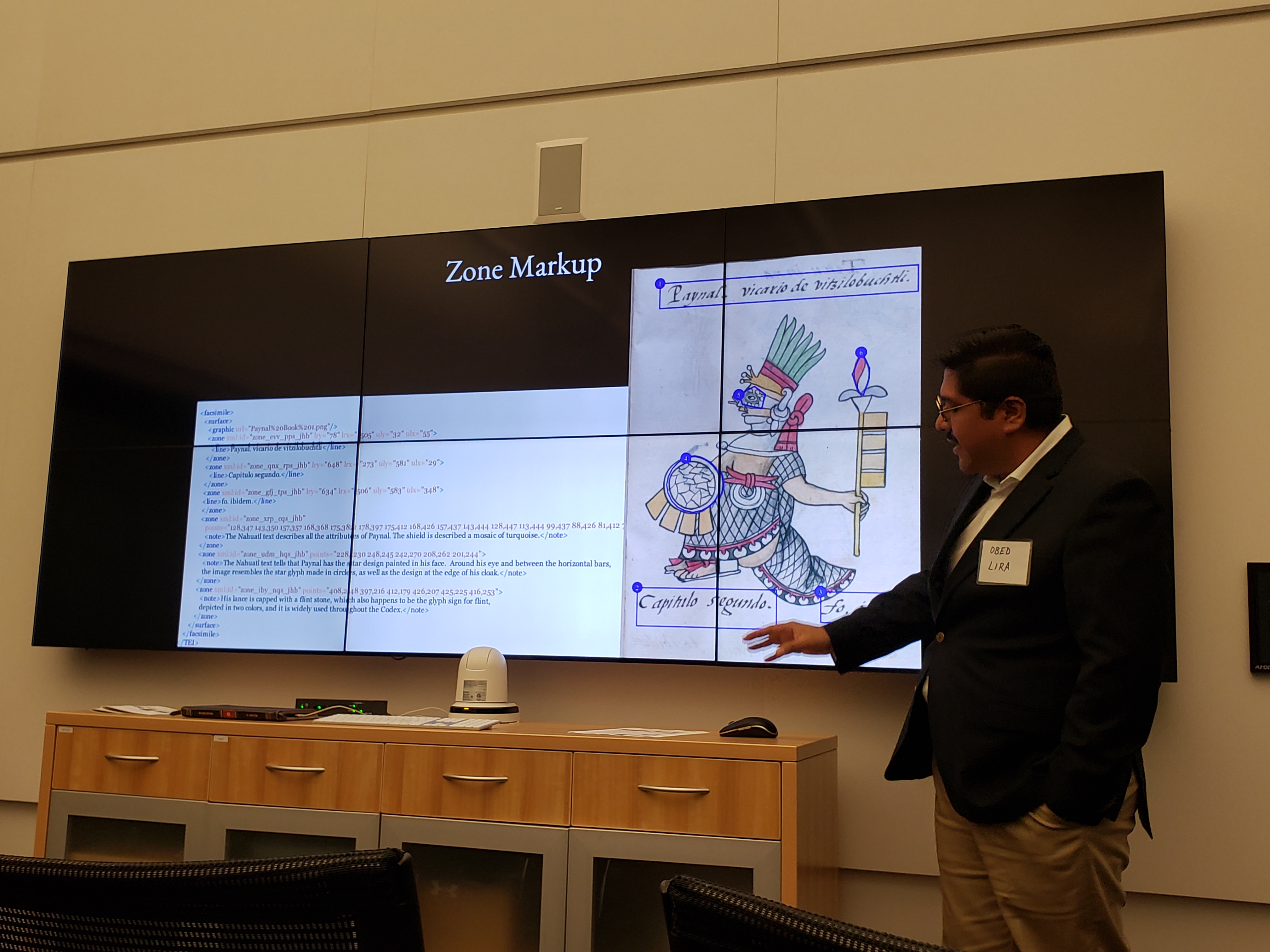
Obed Lira (Bucknell) spoke about a project he’s developing with a team of students to build a decolonial digital edition of the Florentine Codex that centers the visual “presentations, not representations” of the Aztec world and worldview. He described the Florentine Codex itself as “DH in 16th century Mexico”: it took multiple years, ran out of funding, and the funders grew irritated with the cost overruns, unavoidable due to the importance of getting the exact right pigments for use in the images. He described the Franciscans' surveys and interviews with Aztec elders as a form of “cultural suicide”, but one that nonetheless ensured that the old gods — and the Aztec people’s own narrative of the conquest of Mexico — survived in some form. Lira described the images as a “fingerprint” from the previous Aztec ways of depicting ideas, and highlighted some of the work he and his students have done to identify distinctive glyphs within these images that depict earlier Aztec iconography. In addition to the imagery, the Codex is an invaluable source for early Nahuatl. While not all of the Nahuatl text is translated — or translated reliably by Christianizing translators with their own agenda — it is the only record of numerous words that are otherwise lost. The UI approach of making the images (depicting the Aztec worldview) fixed on the page, even as translations can be opened and closed, is a concrete example of how one can take steps towards decolonizing historical documents in DH projects.
Carrie Schroeder (University of the Pacific) described the Coptic Scriptorium, where she and colleagues are developing NLP tools, dictionaries, and corpora, along with infrastructure for collaboration in Coptic studies. This collaborative infrastructure is particularly important in the Coptic scholarly community because it is widely dispersed — rarely is there more than one Coptic scholar at an institution. A partnership with Amir Zeldes, a computational linguist with a personal interest in Coptic but no professional context for applying that interest, provided an ideal collaboration for the project. The project has adapted a number of existing tools for entity annotation and dependency parsing, and has gotten the Coptic treebank listed on the Universal Dependencies website, which was an important goal for them for increasing the visibility of Coptic.
Samantha Blickhan (Zooniverse) described an A/B experiment they ran on individual vs. collaborative methods of crowdsourced transcription (e.g. can second and third transcribers see what others have entered previously?). The result was that the quality increased slightly, but the engagement and completion rate was significantly higher. She has a forthcoming paper with the full results of the study. For myself, this was a heartening result, as someone who’s tried and failed to run a crowdsourced tool directory, where engaging people to continue contributing (even after I no longer had time or funding to do outreach myself) was the biggest problem.
Robert Alessi (Université Paris-Sorbonne) presented on ekdosis, a LuaLaTeX package for multilingual critical editions. The tool is intended for projects where a professionally-formatted print version is an important output. What struck me as especially interesting about this approach was that the documents are meant to be authored (and validated) in LaTeX, and any valid LaTeX file should generate a consistently-encoded TEI version.
The LitLab Translations project team (Yulia Ilchuk, Antonio Lenzo, J.D. Porter, and myself) presented on initial findings from some exploratory text analysis comparing literary texts translated into English with literary texts originally written in English. There are a number of statistically significant features (e.g. greater frequency of including “that” in constructions like “I think that…” vs. “I think…”) that can identify this “translationese”; we need to do some more work to try to pin down specific traits that can be an identifying signal for a given source language. I put the Jupyter notebook and Excel sheet I used to crunch some of the data up on Github, along with metadata about the corpus (they’re modern short stories, so we can’t release the corpus, but you could recreate it).
Kay Ueda and Lisa Nguyen from the Hoover Archive gave a refreshingly frank talk about the challenges they’ve encountered in digitizing Japanese-language diaspora newspapers, which are widely dispersed across the world, and often have to be OCR’d from poor-quality microfilm because the originals no longer exist. Cultural challenges compounded the technical challenges: in East Asia, emphasis is on 100% accuracy in digitized text, which means manual transcription is strongly preferred over automatic OCR. For their project, access (however imperfect) was a bigger priority, which required managing expectations. Their project includes a crowdsourcing option for text correction, the need for which is even more acute than for Japanese OCR in general — which doesn’t produce great results even in the best circumstances, as I discovered while teaching non-English DH last quarter. Because the readers of these newspapers had not necessarily reached full literacy in standard Japanese (including the use of kanji), many texts include phonetic superscript transcriptions (furigana) that further complicate OCR. Creating visual guides for workers at overseas companies to understand Japanese newspaper text layout and flow has been a useful step towards improving the quality of the results, along with many calls at odd hours to jointly evaluate the output of a test set. The talk ended with a moving image from one of these newspapers: a weeping sun, a laborer bearing the load of exclusion (the Exclusion Act, but also technological exclusion, and the exclusion of Japanese-language materials from national corpora like Chronicling America), and the message, “Be patient and do your best. Some day you will win.”
Giovanna Cesarani (Stanford) noted at the beginning of her talk on the Grand Tour Project that “preservation necessitates curation, and curation is never a neutral act”. Taking the “Dictionary of British and Irish Travellers in Italy” as her starting point, she and her team have done a great deal of curation work to create individual entries for people who only appear in passing references (e.g. servants and slaves) or as an aggregate (e.g. “Mr. and Mrs.” so-and-so). As a result, their database now includes records of 900 women, compared to 180 entries in the printed dictionary. They also provide visualizations that aggregate the travels of groups of people who may have never met one another, but whose journey may have been shaped by common forces, such as a shared profession. She asked provocatively, “What does it mean to tell a story about 69 people? Can you name them all in an article?” And noted that visualization preserves everyone’s agency, even if you can’t discuss them individually.
Cecil Brown (writer) spoke about a future digital reconstruction of James Baldwin’s studio in France, noting that “DH allows you to experience places that exist only in the memories of people who were there, and recreate things that were lost” — a particularly poignant thought as images poured in during the workshop of Notre Dame Cathedral burning.
On a personal note, this workshop was only the second time in my adult life that I didn’t skip work / school on my birthday — the first time being for a class in college on endangered languages. The organizers and attendees did not fall short in effecting the ritualistic embarrassment of a group rendition of “Happy Birthday to You”, but perhaps the greatest birthday present of all was the opportunity to find new collaborators and new projects. Zheng Zhang will be spending the next month at an internship at CESTA, and I look forward to working with him on sorting through the Slavic-language translations of “Huck Finn” as a step towards better discovery tools for translation studies scholars.